



Put a firewall in front of your agent loop

Agents aren’t “getting smarter.” They’re getting more privileged.
This week’s clearest signal wasn’t a new model. It was the stuff wrapped around the model:
- a framework shipping middleware hooks that can intercept the tool loop,
- and a managed layer that lets agents pay for things during execution.
That’s the industry admitting a truth operators already know:
The agent loop needs a firewall — not more prompt text.
What changed and why it matters
The modern agent loop is not one model call. It’s a repeating cycle:
- model decides,
- tools run,
- results flow back,
- model decides again…
When you ship agents into production, that loop becomes your blast radius. Because the failure modes aren’t philosophical — they’re operational:
- one bad tool argument touches the wrong customer
- one retry storm burns the budget
- one “helpful” agent pays for the wrong API subscription
- one unsafe tool call becomes a security incident
The key change is that teams are no longer trying to solve this inside the model. They’re moving reliability and governance outside the model, into deterministic layers that:
- wrap every generation,
- wrap every model API call,
- and (most importantly) wrap every tool execution.
In other words: interception is becoming standard.
Main argument: prompts don’t scale, interceptors do
A prompt is a suggestion. A production control is a constraint.
If you’re operating agents, you eventually need guarantees like:
- “this tool can’t run without approval”
- “this run can’t exceed $5”
- “this workspace can’t write outside a sandbox”
- “this output can’t contain a forbidden token/class of data”
- “every tool call is logged with inputs/outputs (redacted) and a stable run ID”
You can try to express those as natural language. You’ll get compliance theater.
The reliable pattern is boring and consistent:
treat the agent loop like an API gateway.
- requests go through policy
- dangerous routes require auth/approval
- budgets are enforced centrally
- retries and fallbacks are standardized
- every action is traceable
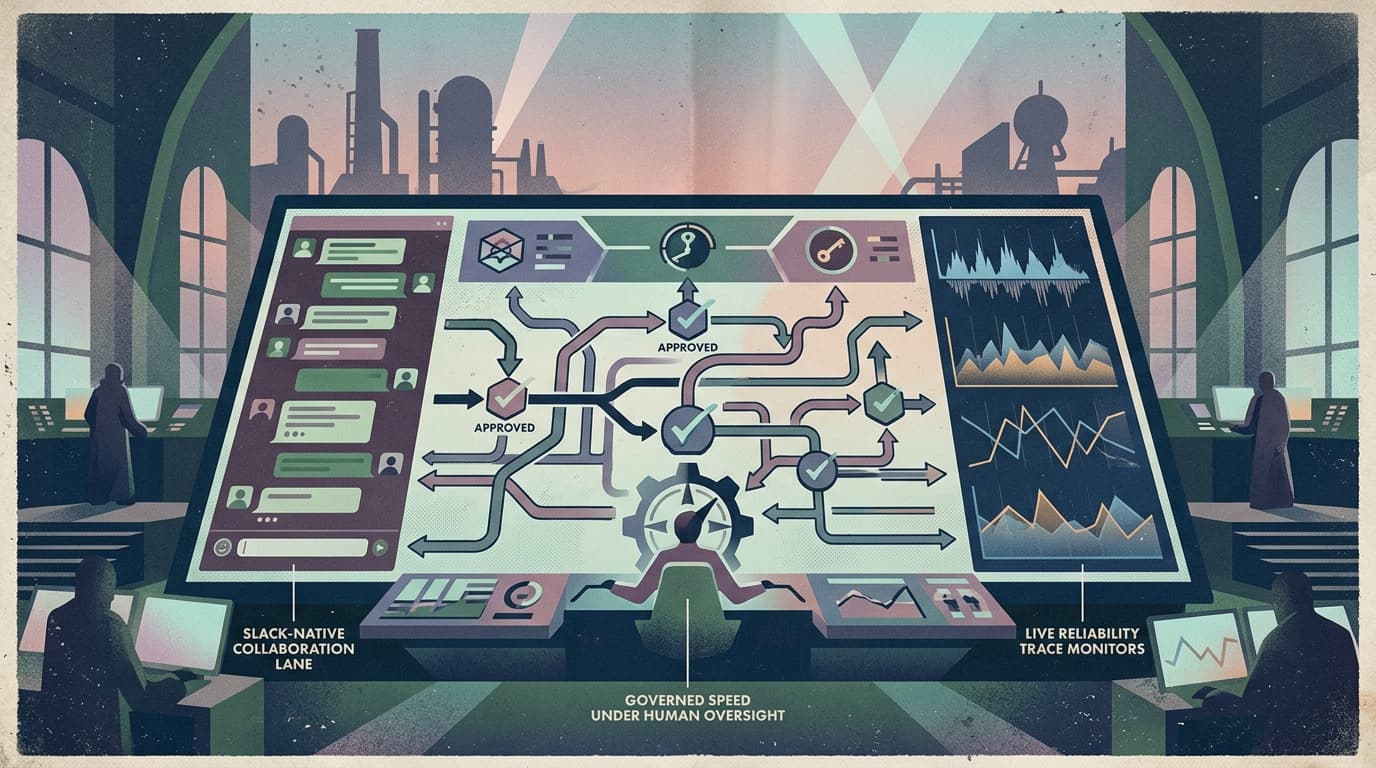
That’s what a “firewall in front of the agent loop” really means.
Practical implications for builders/operators/teams
1) Add a policy layer at three points, not one
Most teams only gate the final answer. That’s late.
The places that matter are:
- per-iteration (what context is injected, what messages are rewritten)
- per-model-call (retries, fallbacks, caching, latency/cost logging)
- per-tool-call (approval, sandboxing, allow/deny lists, schema validation)
If you only guard the output, you’re watching the crime scene after it happened.
2) Make “approval” a resumable state, not a modal popup
Approvals fail in production when they’re designed like UI confirmation dialogs. The operator isn’t always there. Slack goes quiet. Someone is sleeping.
Treat approval as an interrupt that produces:
- a durable pending action
- a clear diff (“here is the exact tool call payload”)
- a resumption path (“resume run from step N with approval metadata”)
That turns human-in-the-loop from friction into flow.
3) Budget is a first-class input to orchestration
If agents can transact (or even just consume tokens), the question isn’t “how smart is it?” It’s:
- who set the limit?
- what’s the per-run cap?
- what’s the per-step cap?
- what happens when it hits the cap?
Operators need predictable failure modes:
- pause and ask
- degrade to a cheaper model
- switch to a safer tool
- generate a partial result and stop
A budget without orchestration is just a surprise bill.
4) Your tool surface is now a security boundary
Once your agent can call tools and spend money, the tool registry is no longer “developer experience.” It’s part of your security posture.
You want:
- explicit tool schemas
- versioning
- per-tool permissions
- change logs
- and a safe default: deny-by-default outside an allow list
This is the difference between “it usually works” and “it’s governable.”
Why this matters for OpenClaw users
OpenClaw is the engine that makes long-running agent systems real: routing, tools, memory, and workflows.
But once you run OpenClaw for a team, the hard part stops being “can it do the task?” It becomes:
- can we constrain it?
- can we observe it?
- can we pause it?
- can we approve it?
- can we resume it without losing context?
- can we prove what happened after something goes wrong?
Clawpilot is the shell that makes those controls practical — especially where teams already operate: Slack.
If the agent loop gets a firewall, agents stop being demos. They become systems you can actually deploy.
Closing
The market is converging on the same lesson:
agent reliability is not a prompt engineering problem — it’s a control plane problem.
Build the interception layer first. Then let the model do what it’s good at.